Apache Impala impala 是 cloudera 提供的一款高效率的 sql 查询工具,提供实时的查询效果 impala 是基于 hive 并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。 Impala 与 Hive 关系 ...
”Impala hadoop“ 的搜索结果

HADOOP 文件系统SHELL; hive批处理、交互式SHELL; IMPALA介绍、支持的命令。
##get_hive_db_tables.sh #!/bin/bash ##脚本位置 where_src_table_info="/home/hadoopap/test_mv_kd/create_hive_table" ##查询大数据所有的database hive -e " show databases; exit ;" | grep -v default | ...
配置hue与impala的集成1.停止hue的服务进程2.重启hue的服务进程 1.停止hue的服务进程 修改hue.ini配置文件 [impala] server_host=node03 server_port=21050 impala_conf_dir=/etc/impala/conf 2.重启hue的...
闪电般的分布式查询,用于存储存储在Apache Hadoop集群中的PB级数据。 Impala是一个现代的,大规模分布,大规模并行的C ++查询引擎,可让您分析,转换和合并来自各种数据源的数据: 同类最佳的性能和可伸缩性。 ...
Impala 驱动包 Cloudera_ImpalaJDBC4_2.5.41.zip Cloudera_ImpalaJDBC41_2.5.41.zip Cloudera-JDBC-Driver-for-Impala-Install-Guide.pdf Cloudera-JDBC-Driver-for-Impala-Release-Notes.pdf
标题1.2.3.4. 1. 2. 3. 4.
hadoop之impala简单使用共8页.pdf.zip
ambari2.7.5集成HDP3,本身不带impala、kudu 故集成cloudera的impala、kudu安装方式 ambari插件安装方式。 解压放到/var/lib/ambari-server/resources/stacks/HDP/3.1/services/下
1. Impala的基本概念 1.1 什么是Impala Impala就是使用SQL语句来操作Hive中的数据库和表,它可以提供低延迟的交互式的SQL查询功能.它与Hive共用表的元数据信息,所以需要使用Impala必须要先有Hive. 1.2 Impala的优...
hadoop impala 随着Hadoop的发展,开发人员获得了具有更多功能的新抽象和发行版本。 Hadoop的新版本和新版本将提供改进的Hadoop,同时消除了早期版本的弊端。 Facebook引入了Apache Hive,以管理和处理存储在...
Centos7原生hadoop环境,搭建Impala集群和负载均衡配置
Hadoop Impala connect hive2 jdbc related Hadoop Impala connect hive2 jdbc related
基于Hadoop的实时查询 Cloudera Impala ,Cloudera 发布实时查询开源项目 Impala (黑斑羚)!多款产品实测表明,比原来基于Map...
Impala A Modern, Open-Source SQL Engine for Hadoop
ambari集成impala-3.0.0依赖cdh版本的hadoop-hbase-hive相关jar包,查hive外部表(基于hbase)
Apache Impala impla是个实时的sql查询工具,类似于hive的操作方式,只不过执行的效率极高,号称当下大数据生态圈中执行效率最高的sql类软件 impala来自于cloudera,后来贡献给了apache impala工作底层执行依赖于...
在Kudu出现之前,Hadoop生态环境中的储存主要依赖HDFS和HBase,追求高吞吐批处理的用例中使用HDFS,追求低延时随机读取用例下用HBase,而Kudu正好能兼顾这两者: ...
http://blog.csdn.net/mayp1/article/details/50952512
提供类SQL的查询语句,能够查询存储在Hadoop的HDFS、Kudu、HBase(实际生产环境中不用)中的PB级大数据。查询速度快是其最大的卖点。简言之impala作为大数据实时查询分析工具,具有查询速度快,灵活性高,易整合,可...
Impala provides fast, interactive SQL queries directly on your Apache Hadoop data stored in HDFS, HBase, or theAmazon Simple Storage Service (S3). In addition to using the same unified storage ...
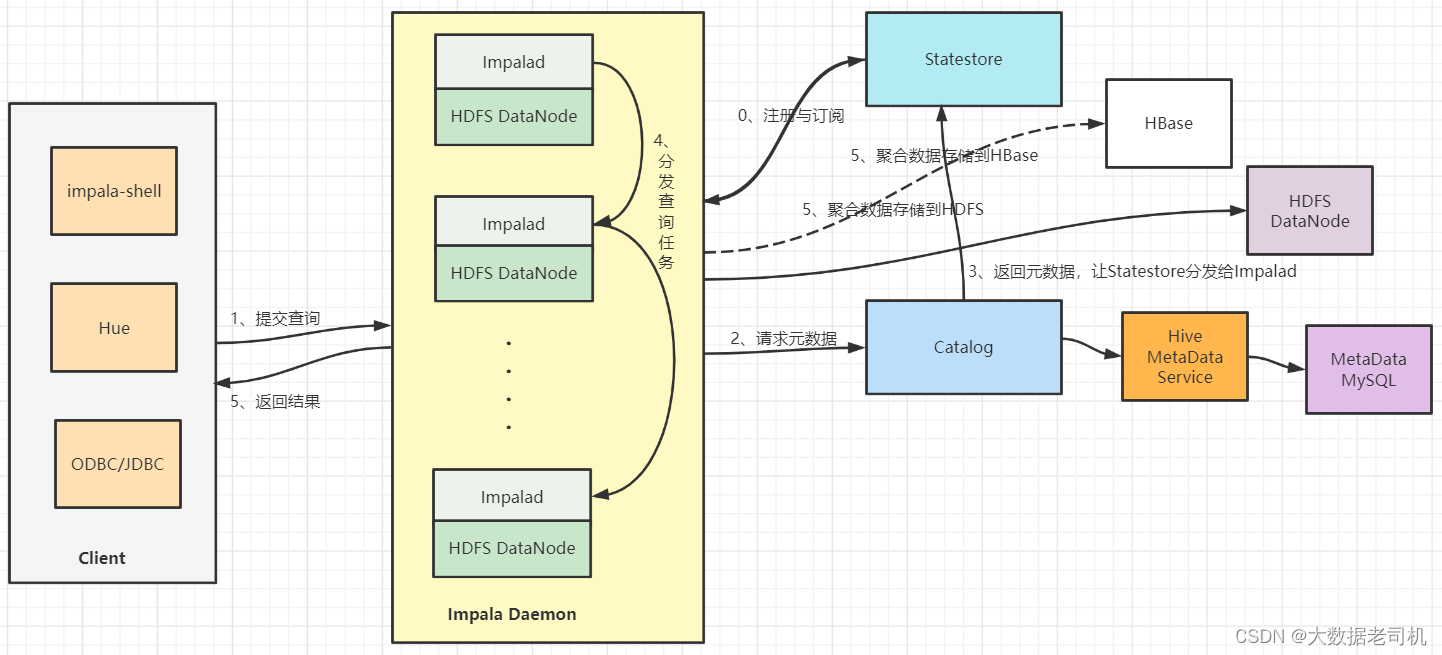
Impala介绍 Impala是实时交互的大数据查询工具 智能的SQL查询 分布式的数据查询 实时的数据查询 Impala体系结构 Impalad:运行于集群中的每一个节点,负责读写文件及处理用户请求 Metastore:负责集群...

一、spark 2.2 需要Kudu 1.5.0以上版本 Spark Integration Known Issues and Limitations Spark 2.2+ requires Java 8 at runtime even though Kudu Spark 2.x integration is Java 7 compatible....
欢迎来到黑斑羚闪电般的分布式查询,用于存储存储在Apache Hadoop集群中的PB级数据。 Impala是一个现代的,大规模分布,大规模并行的C ++查询引擎,可让您分析,转换和合并来自各种数据源的数据: 同类最佳的性能和...
文章目录impalaimpala的架构impala的查询计划impala的安装挂载磁盘 impala impala是cloudera 公司开源提供的一个sql交互查询的工具,兼具hive的优势,具有批量处理以及实时处理等优势。 impala的优点与缺点: impala...
推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地